
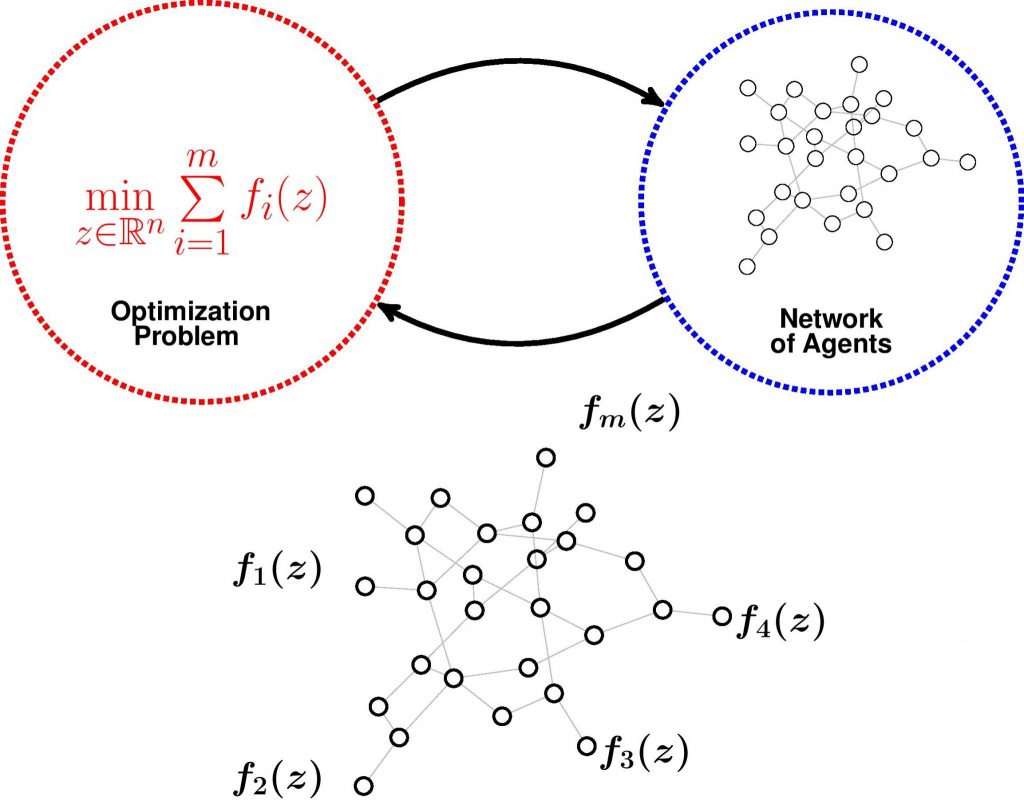
My research goal is to advance the mathematical foundations of optimization and to develop efficient algorithms to solve huge-scale data processing and analysis problems over networks. I am particularly interested in the design of scalable distributed optimization algorithms that execute over networks and perform as well as their centralized counterparts and their applications to statistical inference and belief systems.
Here is an overview of my research

Fundamental Limits of (Distributed) Optimization (Video & Poster)
The seminal work of Nesterov and Nemirovski [1, 2] provided lower bounds on the performance of rst-order methods for convex optimization problems. Consequently, the goal of distributed optimization has been to show convergence rates that match those lower bounds for the same classes of problems. Nevertheless, it is only until recently that new distributed methods have closed the gap between centralized and distributed approaches for some classes of convex problems [3{7]. However, a complete theory of optimal algorithms for distributed optimization is still missing.
A Dual Approach for Optimal Distributed Algorithms
In [8], we develop distributed optimization algorithms with optimal performance (up to logarithmic factors) for strongly convex and smooth functions, as well as only smooth, only strongly convex, or just convex functions. Our results match optimal complexity bounds (in terms of oracle calls) of centralized methods, with an additional cost induced by the communication network. This extra cost appears in the form of an unimprovable multiplicative factor proportional to the square root of the spectral gap of the network. This characterizes the cost of the distributed structure which is linear in the number of agents for worst-case static undirected graphs. These results hold for functions with a dual friendly structure. Nonetheless, we also provide the first available optimal bounds where no dual problem solution is explicitly available. Additionally, we develop optimal methods for problems with a proximal friendly structure and provide ways to improve the condition number.
Optimal Algorithms in Distributed Stochastic Optimization
In construction
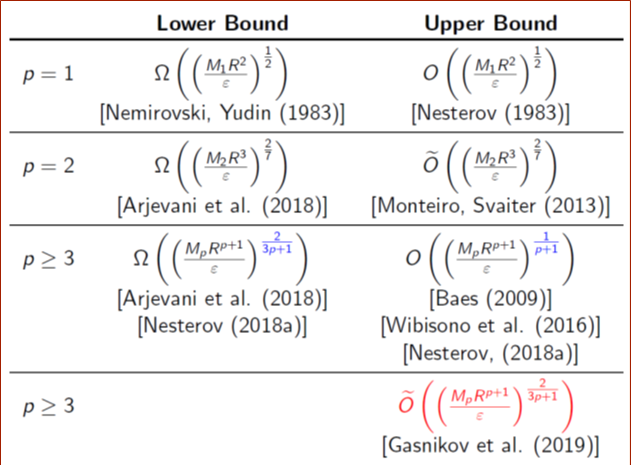
Optimal Algorithms for High-Order Smoothness
Reduced coordination:
Strongly convex and smooth optimization problems can be solved at a geometric rate. However, existing distributed algorithms require further coordination in the sense that the step-sizes need to be equal for all agents. This hinders the goal of a fully distributed execution given that a global step-size somehow needs to be agreed on beforehand between all agents. In [9], we propose the first algorithm that achieves a geometric convergence rate for strongly convex and smooth distributed optimization problems and does not require the global step-size to be known by all the agents in the network. Thus, even if every agent uses a different step-size in its local execution, a linear rate is still guaranteed, effectively reducing coordination requirements without hindering performance.
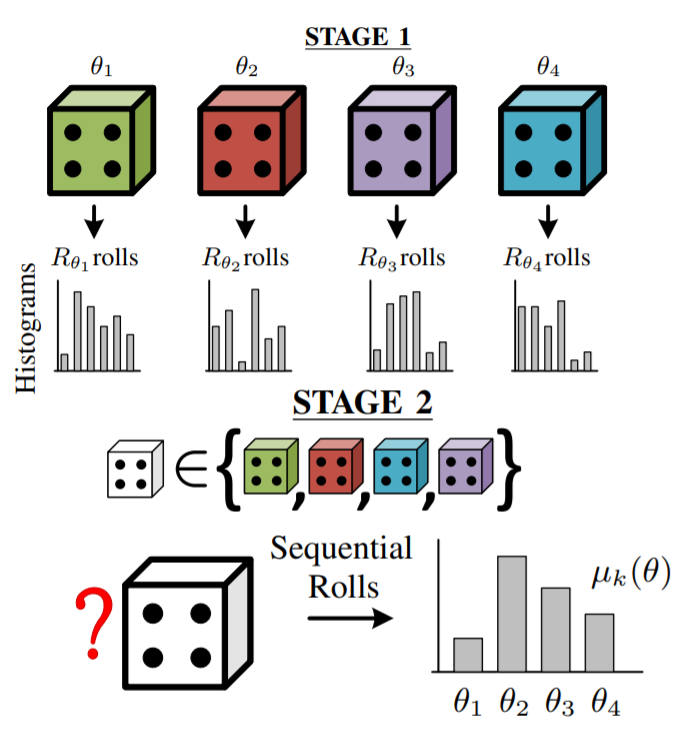
Non-asymptotic Analysis of Distributed Statistical Inference (Video & Poster)
Distributed learning refers to the statistical inference problem where individual agents on a network sequentially observe private data and try to estimate a joint parameter that best describes the complete set of network-wide observations. One can interpret this problem as distributed hypothesis testing where the statistical model, as well as the evidence, is distributed over a network. Each agent constructs local beliefs about the unknown parameter based on local observations and limited communications with others. Learning occurs if the beliefs of all agents concentrate on the true parameter to be estimated. Given that the local information is generated from heterogeneous sources, the main challenge is to guarantee all agents will learn even if the local observations are not enough to identify the optimal parameter correctly and cooperation is needed [10].
Finite Parameter Spaces and Time-varying Directed Graphs
In [11], we provide the first non-asymptotic, explicit and geometric belief concentration rate for distributed learning on finite parameter spaces. Moreover, we show this concentration occurs even if the communication network changes with time but certain minimal connectivity holds.
Interestingly, we found the dependency on the network topology is proportional to the connectivity of the graph sequence. Later in [12], we propose a new algorithm that guarantees all agents in the network will learn in directed networks as well. In [13], we introduce the concept of conflicting hypotheses among agents and show learning occurs even if agents have different statistical models. We provide an explicit convergence rate that shows the concentration of beliefs happens exponentially fast at a rate proportional to the distance between the best and the second-best hypothesis. Furthermore, for fixed undirected graphs, we propose a new algorithm with optimal dependence on the number of agents. We show that the convergence time increases linearly with the size of the network, whereas for other methods this dependency is quadratic or even cubic. This dependency is optimal in the worst-case graph, for example, one can think of a path graph and reason that information takes at least a number of steps proportional to
its length to disperse.
Bayes Posterior is Stochastic Mirror Descent
In [10], we develop a novel variational interpretation of Bayesian inference showing posteriors are exactly stochastic mirror steps when minimizing the Kullback-Leibler divergence in density estimation. This approach allow us to propose a natural extension of Bayesian posteriors to the distributed setting. Indeed, given that not all observations are available at a single location, one cannot talk about a true posterior. However, we show that our formulation guarantees all agents converge to the posterior in the limit. Moreover, we provide explicit non-asymptotic concentration rates. These convergence rates are the first available for distributed learning when the parameter space is a compact subset of the Euclidean space. Working with compact spaces allows the development of easily implementable algorithms for distributed inference on the exponential family of distributions, which covers most of the commonly used distributions such as Gaussian, Poisson and Bernoulli.
Uncertain Models in Distributed Inference
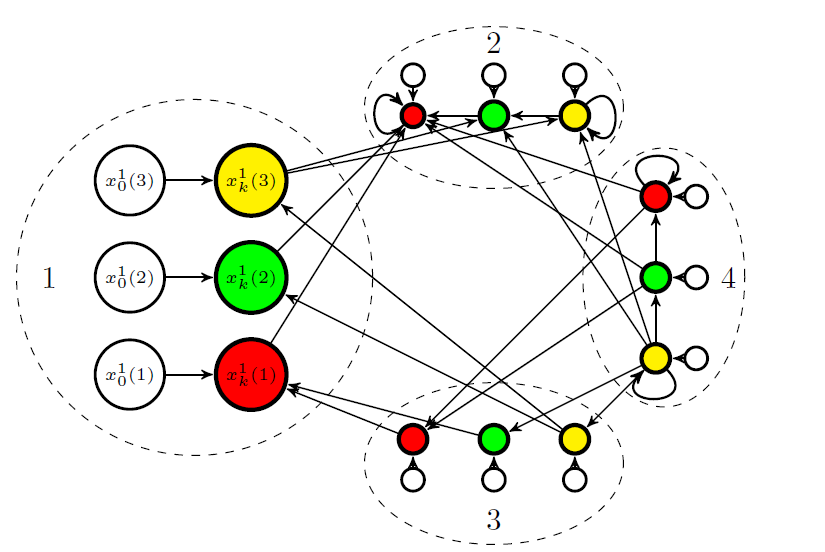
Graph-Theoretic Analysis of Belief Systems
Opinion formation cannot be modeled solely as an ideological deduction from a set of principles; rather, repeated social interactions and logic constraints among statements are consequential in the construct of belief systems. We address three basic questions in the analysis of social opinion dynamics: (i) Will a belief system converge? (ii) How long does it take to converge? (iii) Where does it converge? We provide graph-theoretic answers to these questions for a model of opinion dynamics of a belief system with logic constraints. Our results make plain the implicit dependence of the convergence properties of a belief system on the underlying social network and on the set of logic constraints that relate beliefs on different statements. Moreover, we provide an explicit analysis of a variety of commonly used large-scale network models.
Computational Optimal Transport
Distributed Computation of Wasserstein Barycenters
